刚刚,全球首个超高帧世界模型MoWorld诞生!英伟达含量0,狂飙50帧
刚刚,全球首个超高帧世界模型MoWorld诞生!英伟达含量0,狂飙50帧专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。
来自主题: AI资讯
9111 点击 2026-07-08 16:00
 搜索
搜索
专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。
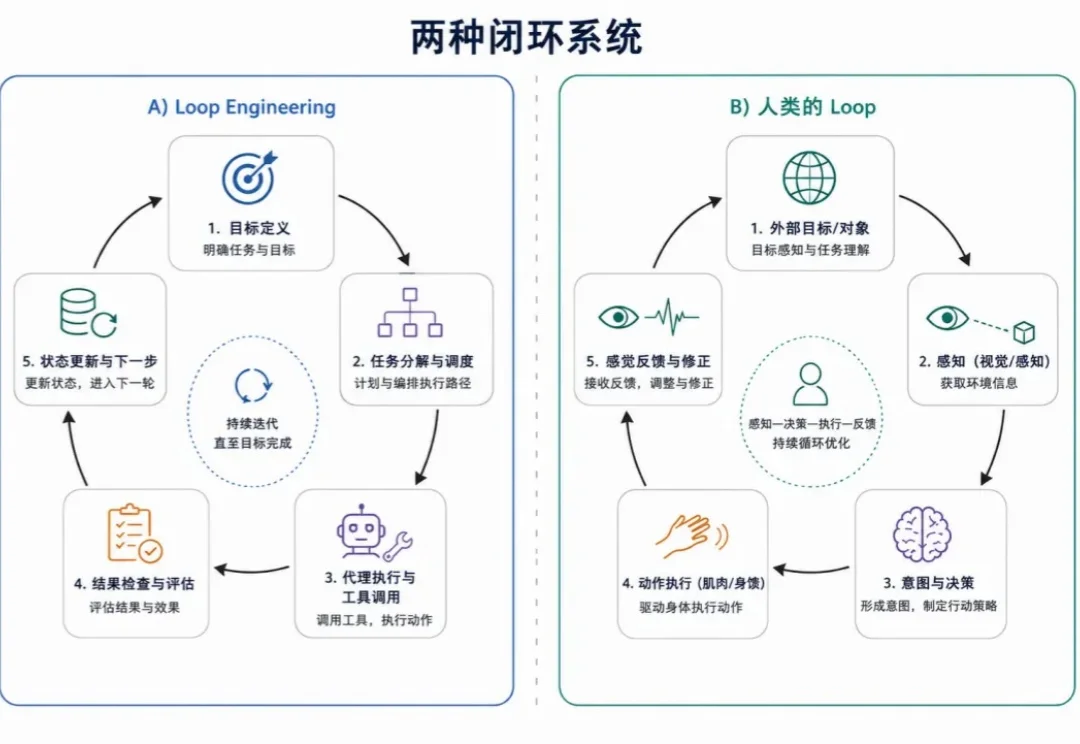
AI 圈最近又热了一个词:Loop Engineering。

投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。
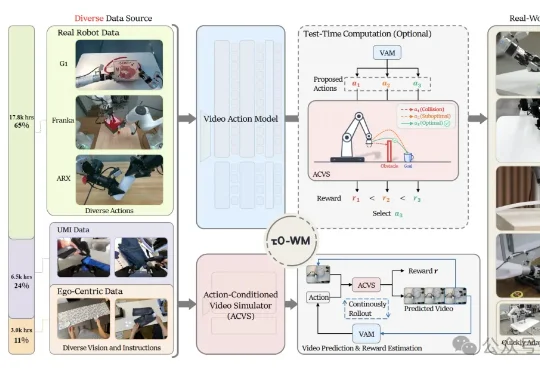
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

即将结束博士生涯的童晟邦,正站在另一个起点上。

刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

世界模型(World Model),想必你已经在很多场合听过这个术语了。它有时出现在视频生成领域,有时又出现在具身智能领域;它们的含义还有所差别,甚至看起来像是完全不同的概念。

为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。
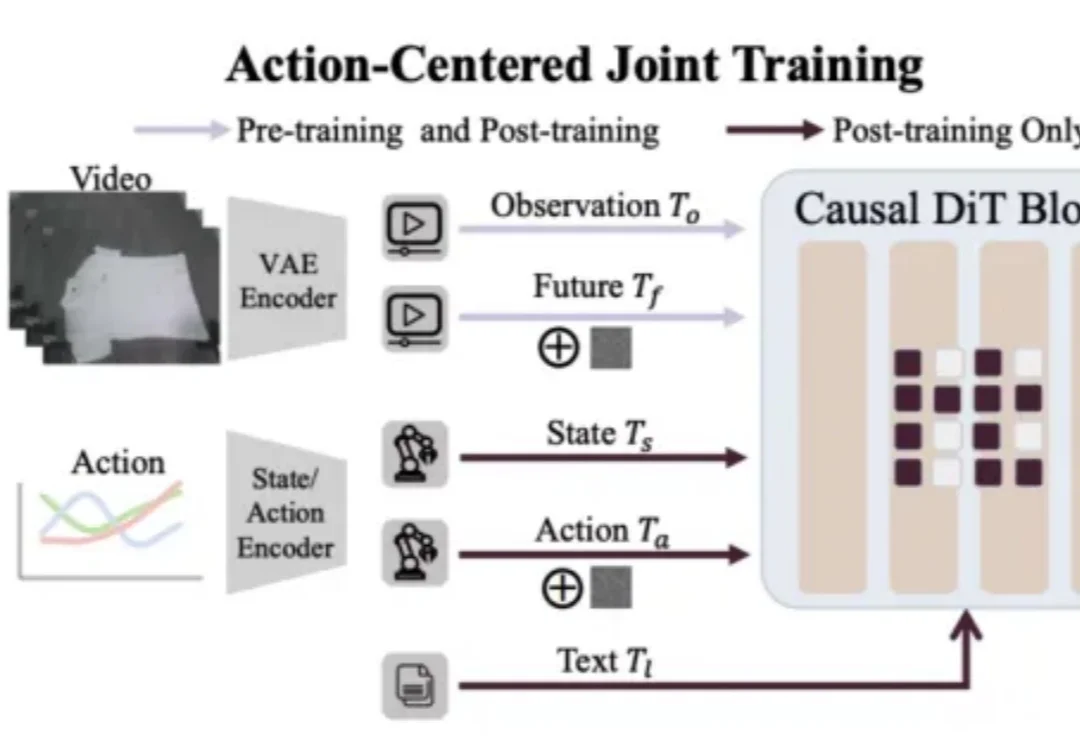
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。